DIN
- 该文主要记录
深度推荐模型|DataWhaleTask5 DIN 内容
Deep Interest Network(DIN) 是阿里发表在 KDD 18 上的一篇论文模型,针对电子商务领域的 CTR 预估,重点在于充分挖掘用户历史行为数据中的信息,考虑用户的历史行为商品与当前商品广告的关联性。
- 使用用户兴趣分布来表示用户多种多样的兴趣爱好
- 使用 Attention 机制来实现 Local Activation
- 针对模型训练,提出了 Dice 激活函数(PReLU),自适应正则(a mini-batch aware regularizer),显著地提升了模型性能与收敛速度
论文在相关工作中介绍说:对于之前的 Wide&Deep、DeepFM 等采用 DNN 应用于 CTR 预测,它们共有的缺点是,并没有针对用户历史行为数据进行分析和建模。这也是 DIN 主要改进的地方,DIN 同时对 Diversity + Local Activation 进行建模。
这里需要介绍一下电子商务领域用户历史数据具有两个非常显著的特征:
- Diversity 兴趣爱好非常广泛
- Local Activation 历史行为中部分数据会主导是否会点击候选广告
针对 Diversity:
针对用户广泛的兴趣,DIN 采用 an interest distribution
针对 Local Activation:
DIN 借鉴机器翻译中的 Attention 机制,设计了一种 Attention-like network structure,针对当前候选 Ad,去局部激活(Local Activate)相关的历史兴趣信息。和当前候选 Ad 相关性越高的历史行为行为,会获得更高的 Attention Score,从而主导这一次预测。
看下最重要的模型结构图
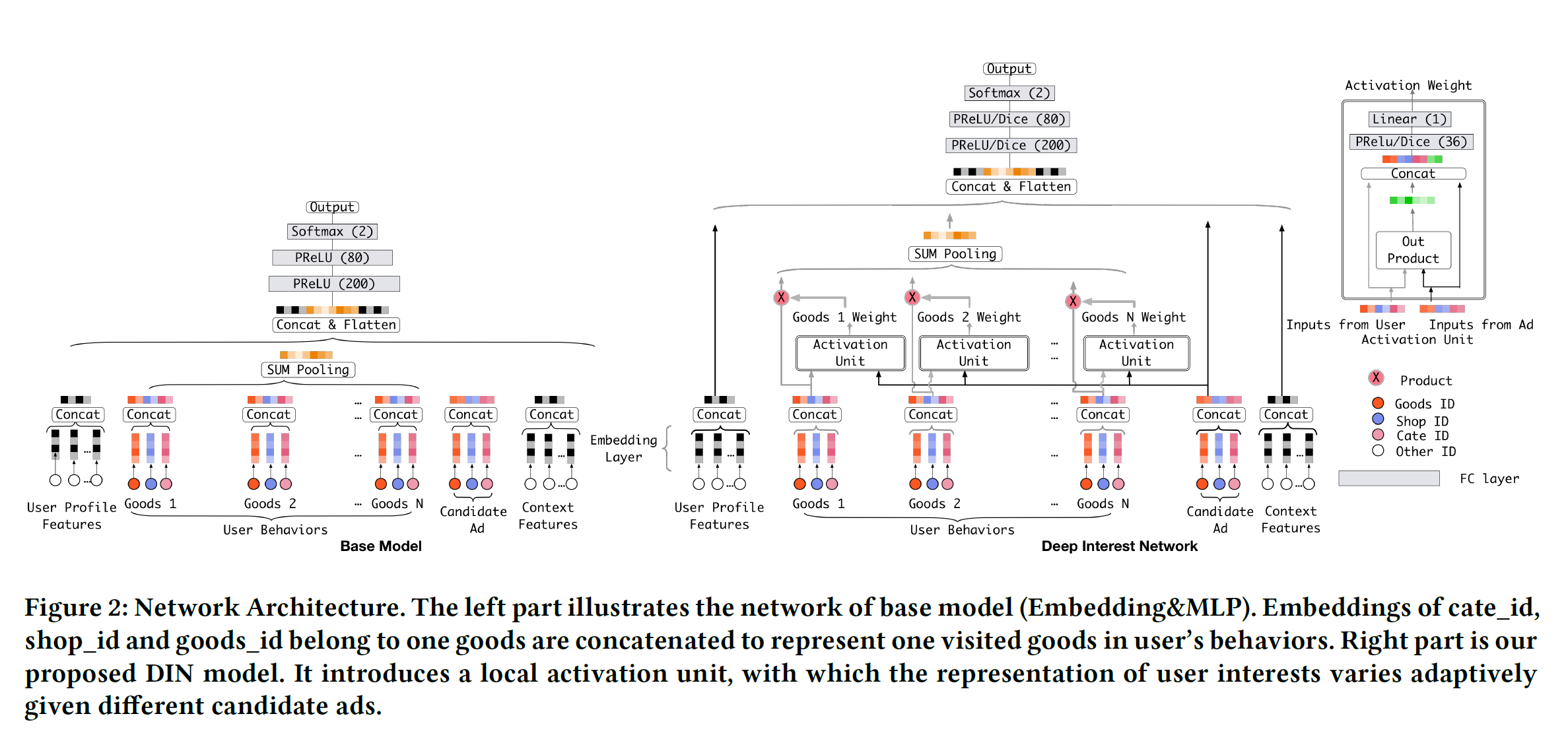
通过引入 Activation Unit 和 Pooling 对两个重要特征进行建模
- Activation Unit 实现 Attention 机制,对 Local Activation 建模
- Pooling(weighted sum)对 Diversity 建模
import warnings
warnings.filterwarnings("ignore")
import itertools
import pandas as pd
import numpy as np
from tqdm import tqdm
from collections import namedtuple
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from deepctr.feature_column import SparseFeat, DenseFeat, VarLenSparseFeat# 设置GPU显存使用,tensorflow不然会报错
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)1 Physical GPUs, 1 Logical GPUs1、Exploratory Data Analysis
samples_data = pd.read_csv("movie_sample.txt", sep="\t", header=None)
samples_data.columns = ["user_id","gender","age","hist_movie_id","hist_len","movie_id","movie_type_id","label"]
samples_data.head()| user_id | gender | age | hist_movie_id | hist_len | movie_id | movie_type_id | label | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 186,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,... | 1 | 112 | 2 | 1 |
| 1 | 1 | 1 | 1 | 186,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,... | 1 | 38 | 5 | 0 |
| 2 | 1 | 1 | 1 | 186,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,... | 1 | 151 | 7 | 0 |
| 3 | 1 | 1 | 1 | 186,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,... | 1 | 77 | 6 | 0 |
| 4 | 1 | 1 | 1 | 186,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,... | 1 | 188 | 9 | 0 |
samples_data.describe()| user_id | gender | age | hist_len | movie_id | movie_type_id | label | |
|---|---|---|---|---|---|---|---|
| count | 1380.000000 | 1380.000000 | 1380.000000 | 1380.000000 | 1380.000000 | 1380.000000 | 1380.000000 |
| mean | 1.991304 | 1.773913 | 1.991304 | 47.430435 | 104.197101 | 4.920290 | 0.166667 |
| std | 0.666126 | 0.418448 | 0.666126 | 34.966080 | 60.739177 | 2.441072 | 0.372813 |
| min | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 0.000000 |
| 25% | 2.000000 | 2.000000 | 2.000000 | 20.000000 | 51.000000 | 3.000000 | 0.000000 |
| 50% | 2.000000 | 2.000000 | 2.000000 | 39.000000 | 105.000000 | 5.000000 | 0.000000 |
| 75% | 2.000000 | 2.000000 | 2.000000 | 71.000000 | 155.250000 | 7.000000 | 0.000000 |
| max | 3.000000 | 2.000000 | 3.000000 | 128.000000 | 208.000000 | 9.000000 | 1.000000 |
print(samples_data["user_id"].unique())
print(samples_data["gender"].unique())
print(samples_data["age"].unique())
print(np.sort(samples_data["movie_id"].unique()))
print(np.sort(samples_data["movie_type_id"].unique()))
print(samples_data["label"].unique())[1 2 3]
[1 2]
[1 2 3]
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108
109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126
127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144
145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162
163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180
181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198
199 200 201 202 203 204 205 206 207 208]
[1 2 3 4 5 6 7 8 9]
[1 0]X = samples_data[["user_id","gender","age","hist_movie_id","hist_len","movie_id","movie_type_id"]]
y = samples_data["label"]X_train = {"user_id": np.array(X["user_id"]),\
"gender": np.array(X["gender"]),\
"age": np.array(X["age"]),\
"hist_movie_id": np.array([[int(i) for i in l.split(",")]for l in X["hist_movie_id"]]),\
"hist_len": np.array(X["hist_len"]),\
"movie_id": np.array(X["movie_id"]),\
"movie_type_id": np.array(X["movie_type_id"])
}
len(X_train)7print(X_train["hist_movie_id"][0])
print(type(X_train["hist_movie_id"][0]))
print(type(X_train["hist_movie_id"]))[186 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0]
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>y_train = np.array(y)# 1. SparseFeat() vocabulary_size = max()+1
# 2. DenseFeat() hist_len
feature_columns = [
SparseFeat("user_id", max(samples_data["user_id"])+1, embedding_dim=8),
SparseFeat("gender", max(samples_data["gender"])+1, embedding_dim=8),
SparseFeat("age", max(samples_data["age"])+1, embedding_dim=8),
SparseFeat("movie_id", max(samples_data["movie_id"])+1, embedding_dim=8),
SparseFeat("movie_type_id", max(samples_data["movie_type_id"])+1, embedding_dim=8),
DenseFeat("hist_len", dimension=1)
]VarLenSparseFeat
VarLenSparseFeat is a namedtuple with signature VarLenSparseFeat(sparsefeat, maxlen, combiner, length_name, weight_name,weight_norm)- sparsefeat : a instance of
SparseFeat - maxlen : maximum length of this feature for all samples
- combiner : pooling method,can be
sum,meanormax - length_name : feature length name,if
None, value 0 in feature is for padding. - weight_name : default
None. If not None, the sequence feature will be multiplyed by the feature whose name isweight_name. - weight_norm : default
True. Whether normalize the weight score or not.
# 从数据上分布中可以得出,len(X_train["hist_movie_id"][0])=50,这也对应着这里的 maxlen设定
# 这里因为使用的导入库为 from deepctr.feature_column import SparseFeat, DenseFeat, VarLenSparseFeat
# 注意下两者的使用区别,这里需要传入的是 SparseFeat 类型和 maxlen
# 源代码:
# from utils import SparseFeat, DenseFeat, VarLenSparseFeat
# feature_columns += [VarLenSparseFeat('hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=50)]
feature_columns += [VarLenSparseFeat(SparseFeat('hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8), maxlen=50)]feature_columns,len(feature_columns),type(feature_columns)([SparseFeat(name='user_id', vocabulary_size=4, embedding_dim=8, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x000001B255B75E50>, embedding_name='user_id', group_name='default_group', trainable=True),
SparseFeat(name='gender', vocabulary_size=3, embedding_dim=8, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x000001B255B757F0>, embedding_name='gender', group_name='default_group', trainable=True),
SparseFeat(name='age', vocabulary_size=4, embedding_dim=8, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x000001B255B75C70>, embedding_name='age', group_name='default_group', trainable=True),
SparseFeat(name='movie_id', vocabulary_size=209, embedding_dim=8, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x000001B255B75D00>, embedding_name='movie_id', group_name='default_group', trainable=True),
SparseFeat(name='movie_type_id', vocabulary_size=10, embedding_dim=8, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x000001B255B75910>, embedding_name='movie_type_id', group_name='default_group', trainable=True),
DenseFeat(name='hist_len', dimension=1, dtype='float32', transform_fn=None),
VarLenSparseFeat(sparsefeat=SparseFeat(name='hist_movie_id', vocabulary_size=209, embedding_dim=8, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x000001B255B90400>, embedding_name='hist_movie_id', group_name='default_group', trainable=True), maxlen=50, combiner='mean', length_name=None, weight_name=None, weight_norm=True)],
7,
list)# 行为特征列表,表示基础特征
behavior_feature_list = ["movie_id"]
# 行为序列特征
behavior_seq_feature_list = ["hist_movie_id"]2、DIN model build
2.1 Input Layers
def build_input_layers(feature_columns):
input_layer_dict = {}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
input_layer_dict[fc.name] = Input(shape=(1, ), name=fc.name)
elif isinstance(fc, DenseFeat):
input_layer_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
elif isinstance(fc, VarLenSparseFeat):
input_layer_dict[fc.name] = Input(shape=(fc.maxlen,), name=fc.name)
return input_layer_dictinput_layer_dict = build_input_layers(feature_columns)
print(input_layer_dict["user_id"], len(input_layer_dict), type(input_layer_dict)),type(input_layer_dict["user_id"])KerasTensor(type_spec=TensorSpec(shape=(None, 1), dtype=tf.float32, name='user_id'), name='user_id', description="created by layer 'user_id'") 7 <class 'dict'># 将 Input 层转化成列表形式作为 model 的输入
input_layers = list(input_layer_dict.values())
input_layers[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'user_id')>,
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'gender')>,
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'movie_id')>,
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'movie_type_id')>,
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'hist_len')>,
<KerasTensor: shape=(None, 50) dtype=float32 (created by layer 'hist_movie_id')>]# 筛选出 sparse and dense
# 注:这里并没有计入 hist_movie_id(VarLenSparseFeat)
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns))2.1.1 Dense 型特征
- Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
dnn_dense_input = []
for fc in dense_feature_columns:
dnn_dense_input.append(input_layer_dict[fc.name])
dnn_dense_input,len(dnn_dense_input)([<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'hist_len')>],
1)# 输入层拼接成列表
def concat_input_list(input_list):
feature_nums = len(input_list)
if feature_nums > 1:
return Concatenate(axis=1)(input_list)
elif feature_nums == 1:
return input_list[0]
else:
return None# 此刻 dnn_dense_input size = 1,因为简化,凭借后的数据和原来一致,
# 但是如果有很多列数据,就还是需要用到拼接
dnn_dense_input = concat_input_list(dnn_dense_input)
dnn_dense_input # dnn dense input for end<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'hist_len')>2.1.2 Sparse 型特征
- Sparse 型特征,为离散型特征建立 Input 层接收输入,然后需要先通过 embedding 层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进 DNN, 但是这里面要注意有个特征的 embedding 向量还得拿出来用,就是候选商品的 embedding 向量,这个还得和后面的计算相关性,对历史行为序列加权。
def build_embedding_layers(feature_columns, input_layer_dict):
embedding_layer_dict = {}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name="emb_"+fc.name)
elif isinstance(fc, VarLenSparseFeat):
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size+1, fc.embedding_dim, name="emb_"+fc.name, mask_zero=True)
return embedding_layer_dict
# 构建 embedding 字典
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
embedding_layer_dict{'user_id': <tensorflow.python.keras.layers.embeddings.Embedding at 0x1b255cddcd0>,
'gender': <tensorflow.python.keras.layers.embeddings.Embedding at 0x1b255cd4fa0>,
'age': <tensorflow.python.keras.layers.embeddings.Embedding at 0x1b255cdd130>,
'movie_id': <tensorflow.python.keras.layers.embeddings.Embedding at 0x1b255cddac0>,
'movie_type_id': <tensorflow.python.keras.layers.embeddings.Embedding at 0x1b255bc93d0>,
'hist_movie_id': <tensorflow.python.keras.layers.embeddings.Embedding at 0x1b255bc95e0>}# 将所有的 sparse 特征 embedding 拼接
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
embedding_list = []
for fc in feature_columns:
_input = input_layer_dict[fc.name]
_embed = embedding_layer_dict[fc.name]
embed = _embed(_input)
if flatten:
embed = Flatten()(embed)
embedding_list.append(embed)
return embedding_list# 将所有的 sparse 特征 embedding 拼接
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
dnn_sparse_embed_input [<KerasTensor: shape=(None, 8) dtype=float32 (created by layer 'flatten')>,
<KerasTensor: shape=(None, 8) dtype=float32 (created by layer 'flatten_1')>,
<KerasTensor: shape=(None, 8) dtype=float32 (created by layer 'flatten_2')>,
<KerasTensor: shape=(None, 8) dtype=float32 (created by layer 'flatten_3')>,
<KerasTensor: shape=(None, 8) dtype=float32 (created by layer 'flatten_4')>]dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
dnn_sparse_input # dnn sparse input for end<KerasTensor: shape=(None, 40) dtype=float32 (created by layer 'concatenate')>2.2 VarlenSparse 型特征
behavior_feature_list['movie_id']behavior_seq_feature_list['hist_movie_id']def embedding_lookup(feature_columns, input_layer_dict, embedding_layer_dict):
embedding_list = []
for fc in feature_columns:
_input = input_layer_dict[fc]
_embed = embedding_layer_dict[fc]
embed = _embed(_input)
# 未进行 Flatten
embedding_list.append(embed)
return embedding_listquery_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
query_embed_list[<KerasTensor: shape=(None, 1, 8) dtype=float32 (created by layer 'emb_movie_id')>]keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
keys_embed_list[<KerasTensor: shape=(None, 50, 8) dtype=float32 (created by layer 'emb_hist_movie_id')>]2.2.1 Dice: Data Dependent Activation Function
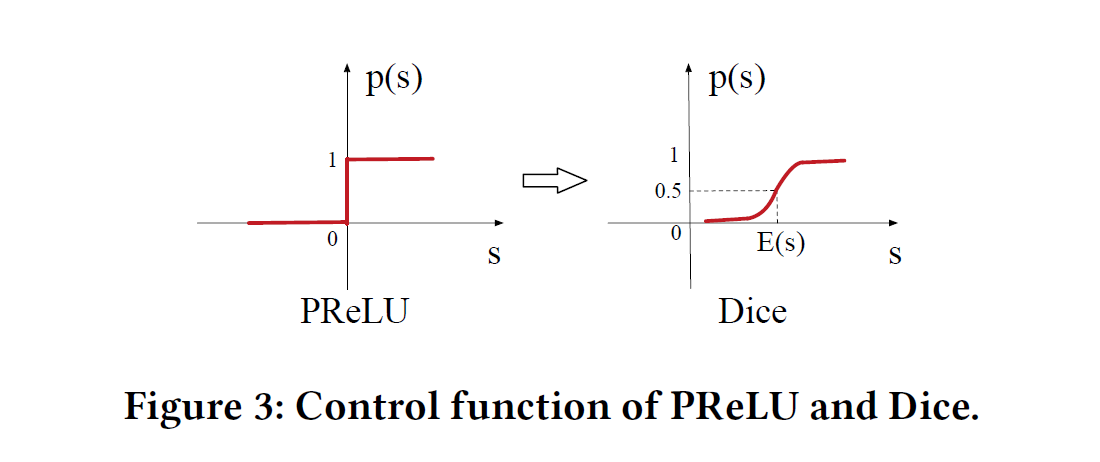
PReLU 是 ReLU 的改良版,ReLU 可以看作是x*Max(x,0),相当于输出 x 经过了一个在 0 点的阶跃整流器。由于 ReLU 在 x 小于 0 的时候,梯度为 0,可能导致网络停止更新,PReLU 对整流器的左半部分形式进行了修改,使得 x 小于 0 时输出不为 0。
研究表明,PReLU 能提高准确率但是也稍微增加了过拟合的风险。PReLU 形式如下:
无论是 ReLU 还是 PReLU 突变点都在 0,论文里认为,对于所有输入不应该都选择 0 点为突变点而是应该依赖于数据的。于是提出了一种 data dependent 的方法:Dice 激活函数。形式如下:
可以看出,$P(s)$是一个概率值,这个概率值决定着输出是取$\alpha s,$或者是$s$,$P(s)$也起到了一个整流器的作用。
class Dice(Layer):
def __init__(self):
super(Dice, self).__init__()
self.bn = BatchNormalization(center=False, scale=False)
def build(self, input_shape):
self.alpha = self.add_weight(shape=(input_shape[-1],), dtype=tf.float32, name="alpha")
def call(self, x):
x_normed = self.bn(x)
x_p = tf.sigmoid(x_normed)
return self.alpha * (1.0-x_p) * x+x_p * x
2.2.2 注意力机制
Attention 机制就是通过计算 query 与各个 key 的相似性,得到每个 key 的权重系数,再通过对 value 加权求和,得到最终 attention 数值。
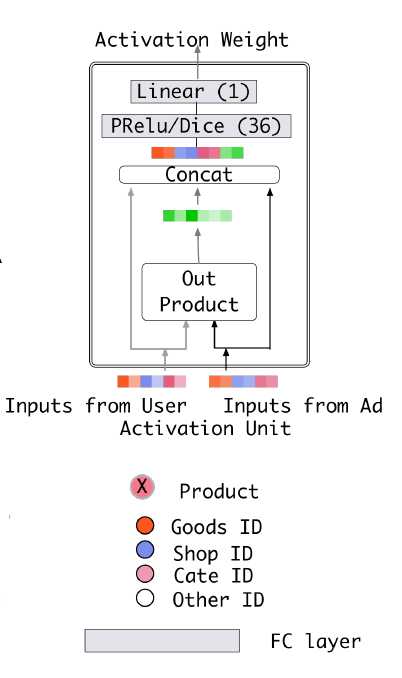
tf.concat([queries, keys, queries-keys, queries*keys], axis=-1) 这一部分并不是理解,参考下别人的解读:
这是个小细节,其实很多算法都有各种解释,比如这个差我们可以解释为差距,这个乘积我们可以解释为高阶信息。
但是真正背后的思考是,在线系统的 latency 是要求很严格的,而 attention 部分的计算是发生在 target item 和 user 的 behavior list 之间的,同时在线打分的时候每次要计算几百个target item的CTR。这使得attention部分的计算复杂度增加一点,在线的计算压力就会增加非常多,所以attention unit必须设计得足够简单。如果这个地方没什么限制显然把attention unit的神经网络加深就好了,但是有限制,我们希望计算简单效果又好,就凭经验加了一个差和一个乘积,用先验的知识降低模型拟合的难度,在线实验验证也有效就在公开数据集也加上了。
class LocalActivationUnit(Layer):
def __init__(self, hidden_units=(256, 128, 64), activation="prelu"):
super(LocalActivationUnit, self).__init__()
self.hidden_units = hidden_units
self.linear = Dense(1)
self.dnn = [Dense(unit, activation=PReLU() if activation=="prelu" else Dice()) for unit in hidden_units]
def call(self, inputs):
# query: B x 1 x emb_dim keys: B x len x emb_dim
# query: shape=(None, 1, 8) keys: shape=(None, 50, 8)
query, keys = inputs
# 获取序列长度
keys_len = keys.get_shape()[1]
# 重复 query 特征,得到 queries,使得 queries 的 shape 与 keys 一致
# tf.tile为复制函数,1代表在该维度上保持一致,keys_len 表示在该维度上 x Keys_len
queries = tf.tile(query, multiples=[1, keys_len, 1]) # (None, len, emb_dim)
# 特征拼接
# B x len(50) x 4*emb_dim(8)
att_input = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
att_out = att_input
for fc in self.dnn:
att_out = fc(att_out) # B x len x att_out
att_out = self.linear(att_out)
att_out = tf.squeeze(att_out, -1)
return att_outclass AttentionPoolingLayer(Layer):
def __init__(self, att_hidden_units=(256, 128, 64)):
super(AttentionPoolingLayer, self).__init__()
self.att_hidden_units = att_hidden_units
self.local_att = LocalActivationUnit(self.att_hidden_units)
def call(self, inputs):
queries, keys = inputs
key_masks = tf.not_equal(keys[:,:,0],0)
attention_score = self.local_att([queries, keys])
paddings = tf.zeros_like(attention_score)
outputs = tf.where(key_masks, attention_score, paddings)
outputs = tf.expand_dims(outputs, axis=1)
outputs = tf.matmul(outputs, keys)
outputs = tf.squeeze(outputs, axis=1)
return outputs
dnn_seq_input_list = []
for i in range(len(keys_embed_list)):
# 记得想 AttentionPoolingLayer()() 这种调用方式为什么可行
seq_emb = AttentionPoolingLayer()([query_embed_list[i], keys_embed_list[i]])
dnn_seq_input_list.append(seq_emb)
dnn_seq_input_list[<KerasTensor: shape=(None, 8) dtype=float32 (created by layer 'attention_pooling_layer')>]# 这里数据 size = 1
dnn_seq_input = concat_input_list(dnn_seq_input_list)
dnn_seq_input # dnn seq input for end<KerasTensor: shape=(None, 8) dtype=float32 (created by layer 'attention_pooling_layer')>2.3 DNN
经过上面步骤的处理, 得到了处理好的连续特征(Dense),离散特征(Sparse)和变长离散特征(VarlenSparse), 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。
# 1 + 40 + 8 = 49
dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
dnn_input<KerasTensor: shape=(None, 49) dtype=float32 (created by layer 'concatenate_1')>def get_dnn_logits(dnn_input, hidden_units=(200, 80), activation='prelu'):
dnns = [Dense(unit, activation=PReLU() if activation == 'prelu' else Dice()) for unit in hidden_units]
dnn_out = dnn_input
for dnn in dnns:
dnn_out = dnn(dnn_out)
# 获取logits
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
return dnn_logitsdnn_logits = get_dnn_logits(dnn_input, activation="prelu")
dnn_logits<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'dense_6')>2.4 Output
model = Model(input_layers, dnn_logits)model.summary()Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
user_id (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
gender (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
age (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
movie_id (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
movie_type_id (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
emb_user_id (Embedding) (None, 1, 8) 32 user_id[0][0]
__________________________________________________________________________________________________
emb_gender (Embedding) (None, 1, 8) 24 gender[0][0]
__________________________________________________________________________________________________
emb_age (Embedding) (None, 1, 8) 32 age[0][0]
__________________________________________________________________________________________________
emb_movie_id (Embedding) (None, 1, 8) 1672 movie_id[0][0]
movie_id[0][0]
__________________________________________________________________________________________________
emb_movie_type_id (Embedding) (None, 1, 8) 80 movie_type_id[0][0]
__________________________________________________________________________________________________
hist_movie_id (InputLayer) [(None, 50)] 0
__________________________________________________________________________________________________
flatten (Flatten) (None, 8) 0 emb_user_id[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 8) 0 emb_gender[0][0]
__________________________________________________________________________________________________
flatten_2 (Flatten) (None, 8) 0 emb_age[0][0]
__________________________________________________________________________________________________
flatten_3 (Flatten) (None, 8) 0 emb_movie_id[0][0]
__________________________________________________________________________________________________
flatten_4 (Flatten) (None, 8) 0 emb_movie_type_id[0][0]
__________________________________________________________________________________________________
emb_hist_movie_id (Embedding) (None, 50, 8) 1680 hist_movie_id[0][0]
__________________________________________________________________________________________________
hist_len (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 40) 0 flatten[0][0]
flatten_1[0][0]
flatten_2[0][0]
flatten_3[0][0]
flatten_4[0][0]
__________________________________________________________________________________________________
attention_pooling_layer (Attent (None, 8) 72065 emb_movie_id[1][0]
emb_hist_movie_id[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 49) 0 hist_len[0][0]
concatenate[0][0]
attention_pooling_layer[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 200) 10200 concatenate_1[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (None, 80) 16160 dense_4[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 1) 81 dense_5[0][0]
==================================================================================================
Total params: 102,026
Trainable params: 102,026
Non-trainable params: 0
__________________________________________________________________________________________________model.compile("adam", "binary_crossentropy")model.fit(X_train, y_train, batch_size=64, epochs=10, validation_split=0.3)Epoch 1/10
16/16 [==============================] - 3s 63ms/step - loss: 1.1904 - val_loss: 0.6021
Epoch 2/10
16/16 [==============================] - 0s 16ms/step - loss: 0.6891 - val_loss: 0.4746
Epoch 3/10
16/16 [==============================] - 0s 15ms/step - loss: 0.6261 - val_loss: 0.4656
Epoch 4/10
16/16 [==============================] - 0s 16ms/step - loss: 0.4625 - val_loss: 0.4673
Epoch 5/10
16/16 [==============================] - 0s 16ms/step - loss: 0.4636 - val_loss: 0.5309
Epoch 6/10
16/16 [==============================] - 0s 15ms/step - loss: 0.4115 - val_loss: 0.6260
Epoch 7/10
16/16 [==============================] - 0s 15ms/step - loss: 0.3869 - val_loss: 0.7247
Epoch 8/10
16/16 [==============================] - 0s 16ms/step - loss: 0.3497 - val_loss: 0.7432
Epoch 9/10
16/16 [==============================] - 0s 15ms/step - loss: 0.3128 - val_loss: 0.7747
Epoch 10/10
16/16 [==============================] - 0s 16ms/step - loss: 0.3241 - val_loss: 0.98363、 思考
DIN模型在工业上的应用还是比较广泛的, 大家可以自由去通过查资料看一下具体实践当中这个模型是怎么用的? 有什么问题?比如行为序列的制作是否合理, 如果时间间隔比较长的话应不应该分一下段? 再比如注意力机制那里能不能改成别的计算注意力的方式会好点?(我们也知道注意力机制的方式可不仅DNN这一种), 再比如注意力权重那里该不该加softmax? 这些其实都是可以值的思考探索的一些问题,根据实际的业务场景,大家也可以总结一些更加有意思的工业上应用该模型的技巧和tricks,欢迎一块讨论和分享。
Common Feature Trick
对于一个用户,一次 pageview 中假设展示了 200 个商品。那么每个商品就对应一条样本。但是,这 200 条样本中是有很多Common Feature的。所以 DIN 的实现中并没有把用户都展开,类似于下图:
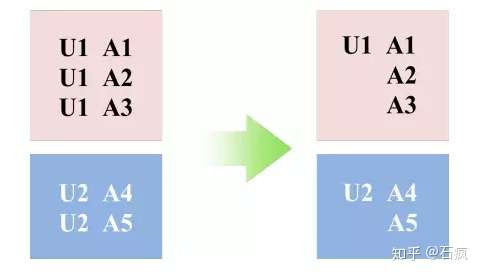
对于很多静态的不变的特征,比如性别、年龄、昨天以前的行为等只计算一次、存储一次。之后利用索引与其他特征关联,大幅度的压缩了样本的存储,加快了模型的训练。最终实验仅用了 1/3 的资源,获得了 12 倍的加速。
- 在模型学习优化上,DIN提出了Dice激活函数、自适应正则 ,显著的提升了模型性能与收敛速度。


