DeepCrossing
- 该文主要记录
深度推荐模型|DataWhale学习内容,记录 Coding 过程和思路,代码格式上并不规范
Deep Crossing模型是由微软研究院在论文《Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features》中提出的,它主要是用来解决大规模特征自动组合问题,从而减轻或者避免手工进行特征组合的开销。Deep Crossing可以说是深度学习CTR模型的最典型和基础性的模型。
import warnings
warnings.filterwarnings("ignore")
import itertools
import pandas as pd
import numpy as np
from tqdm import tqdm
from collections import namedtuple
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from deepctr.feature_column import SparseFeat, DenseFeat, VarLenSparseFeat# 设置GPU显存使用,tensorflow不然会报错
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)1 Physical GPUs, 1 Logical GPUs一、Load Dataset
data = pd.read_csv("./代码/data/criteo_sample.txt")
columns = data.columns.values
columnsarray(['label', 'I1', 'I2', 'I3', 'I4', 'I5', 'I6', 'I7', 'I8', 'I9',
'I10', 'I11', 'I12', 'I13', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6',
'C7', 'C8', 'C9', 'C10', 'C11', 'C12', 'C13', 'C14', 'C15', 'C16',
'C17', 'C18', 'C19', 'C20', 'C21', 'C22', 'C23', 'C24', 'C25',
'C26'], dtype=object)# 划分 dense 和 sparse 特征
dense_features = [i for i in columns if 'I' in i]
sparse_features = [i for i in columns if 'C' in i]
print(dense_features)
print(sparse_features)['I1', 'I2', 'I3', 'I4', 'I5', 'I6', 'I7', 'I8', 'I9', 'I10', 'I11', 'I12', 'I13']
['C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10', 'C11', 'C12', 'C13', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'C22', 'C23', 'C24', 'C25', 'C26']data[dense_features].head()| I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | I10 | I11 | I12 | I13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 3 | 260.0 | NaN | 17668.0 | NaN | NaN | 33.0 | NaN | NaN | NaN | 0.0 | NaN |
| 1 | NaN | -1 | 19.0 | 35.0 | 30251.0 | 247.0 | 1.0 | 35.0 | 160.0 | NaN | 1.0 | NaN | 35.0 |
| 2 | 0.0 | 0 | 2.0 | 12.0 | 2013.0 | 164.0 | 6.0 | 35.0 | 523.0 | 0.0 | 3.0 | NaN | 18.0 |
| 3 | NaN | 13 | 1.0 | 4.0 | 16836.0 | 200.0 | 5.0 | 4.0 | 29.0 | NaN | 2.0 | NaN | 4.0 |
| 4 | 0.0 | 0 | 104.0 | 27.0 | 1990.0 | 142.0 | 4.0 | 32.0 | 37.0 | 0.0 | 1.0 | NaN | 27.0 |
data[sparse_features].head()| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | ... | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 05db9164 | 08d6d899 | 9143c832 | f56b7dd5 | 25c83c98 | 7e0ccccf | df5c2d18 | 0b153874 | a73ee510 | 8f48ce11 | ... | e5ba7672 | 87c6f83c | NaN | NaN | 0429f84b | NaN | 3a171ecb | c0d61a5c | NaN | NaN |
| 1 | 68fd1e64 | 04e09220 | 95e13fd4 | a1e6a194 | 25c83c98 | fe6b92e5 | f819e175 | 062b5529 | a73ee510 | ab9456b4 | ... | d4bb7bd8 | 6fc84bfb | NaN | NaN | 5155d8a3 | NaN | be7c41b4 | ded4aac9 | NaN | NaN |
| 2 | 05db9164 | 38a947a1 | 3f55fb72 | 5de245c7 | 30903e74 | 7e0ccccf | b72ec13d | 1f89b562 | a73ee510 | acce978c | ... | e5ba7672 | 675c9258 | NaN | NaN | 2e01979f | NaN | bcdee96c | 6d5d1302 | NaN | NaN |
| 3 | 05db9164 | 8084ee93 | 02cf9876 | c18be181 | 25c83c98 | NaN | e14874c9 | 0b153874 | 7cc72ec2 | 2462946f | ... | e5ba7672 | 52e44668 | NaN | NaN | e587c466 | NaN | 32c7478e | 3b183c5c | NaN | NaN |
| 4 | 05db9164 | 207b2d81 | 5d076085 | 862b5ba0 | 25c83c98 | fbad5c96 | 17c22666 | 0b153874 | a73ee510 | 534fc986 | ... | e5ba7672 | 25c88e42 | 21ddcdc9 | b1252a9d | 0e8585d2 | NaN | 32c7478e | 0d4a6d1a | 001f3601 | 92c878de |
5 rows × 26 columns
data["C1"].shape,type(data["C1"])((200,), pandas.core.series.Series)二、Data Process and LabelEncoder
sklearn.preprocessing.LabelEncoder
Encode target labels with value between 0 and n_classes-1.
This transformer should be used to encode target values, i.e. y, and not the input X.
Examples
LabelEncoder can be used to normalize labels.
>>> from sklearn import preprocessing
>>> le = preprocessing.LabelEncoder()
>>> le.fit([1, 2, 2, 6])
LabelEncoder()
>>> le.classes_
array([1, 2, 6])
>>> le.transform([1, 1, 2, 6])
array([0, 0, 1, 2]...)
>>> le.inverse_transform([0, 0, 1, 2])
array([1, 1, 2, 6])It can also be used to transform non-numerical labels (as long as they are hashable and comparable) to numerical labels.
>>> le = preprocessing.LabelEncoder()
>>> le.fit(["paris", "paris", "tokyo", "amsterdam"])
LabelEncoder()
>>> list(le.classes_)
['amsterdam', 'paris', 'tokyo']
>>> le.transform(["tokyo", "tokyo", "paris"])
array([2, 2, 1]...)
>>> list(le.inverse_transform([2, 2, 1]))
['tokyo', 'tokyo', 'paris']Methods
fit(y) |
Fit label encoder. |
|---|---|
fit_transform(y) |
Fit label encoder and return encoded labels. |
get_params([deep]) |
Get parameters for this estimator. |
inverse_transform(y) |
Transform labels back to original encoding. |
set_params(**params) |
Set the parameters of this estimator. |
transform(y) |
Transform labels to normalized encoding. |
data[dense_features] = data[dense_features].fillna(0.0)
for i in dense_features:
data[i] = data[i].apply(lambda x: np.log(x+1) if x>-1 else -1)
data[sparse_features] = data[sparse_features].fillna("-1")
for i in sparse_features:
lbe = LabelEncoder()
data[i] = lbe.fit_transform(data[i])data[dense_features].head()| I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | I10 | I11 | I12 | I13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.625800 | 1.058373 | 0.000000 | 1.217181 | 0.000000 | 0.000000 | 0.920250 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 |
| 1 | 0.0 | -1.000000 | 0.869294 | 0.925237 | 1.231491 | 1.055658 | 0.423036 | 0.925237 | 1.031488 | 0.0 | 0.423036 | 0.0 | 0.925237 |
| 2 | 0.0 | 0.000000 | 0.554618 | 0.820286 | 1.148252 | 1.032922 | 0.732569 | 0.925237 | 1.092790 | 0.0 | 0.625800 | 0.0 | 0.863863 |
| 3 | 0.0 | 0.829305 | 0.423036 | 0.672503 | 1.215852 | 1.044182 | 0.706395 | 0.672503 | 0.909015 | 0.0 | 0.554618 | 0.0 | 0.672503 |
| 4 | 0.0 | 0.000000 | 1.005164 | 0.902628 | 1.147829 | 1.024444 | 0.672503 | 0.917610 | 0.929876 | 0.0 | 0.423036 | 0.0 | 0.902628 |
data[sparse_features].head()| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | ... | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 4 | 96 | 146 | 1 | 4 | 163 | 1 | 1 | 72 | ... | 8 | 66 | 0 | 0 | 3 | 0 | 1 | 96 | 0 | 0 |
| 1 | 11 | 1 | 98 | 98 | 1 | 6 | 179 | 0 | 1 | 89 | ... | 7 | 52 | 0 | 0 | 47 | 0 | 7 | 112 | 0 | 0 |
| 2 | 0 | 18 | 39 | 52 | 3 | 4 | 140 | 2 | 1 | 93 | ... | 8 | 49 | 0 | 0 | 25 | 0 | 6 | 53 | 0 | 0 |
| 3 | 0 | 45 | 7 | 117 | 1 | 0 | 164 | 1 | 0 | 20 | ... | 8 | 37 | 0 | 0 | 156 | 0 | 0 | 32 | 0 | 0 |
| 4 | 0 | 11 | 59 | 77 | 1 | 5 | 18 | 1 | 1 | 45 | ... | 8 | 14 | 5 | 3 | 9 | 0 | 0 | 5 | 1 | 47 |
5 rows × 26 columns
# 源代码使用的 data_process() 处理,
# 需要留意 python 浅拷贝和深拷贝,源数据本身也会被操作
train_data = data
train_data.head()| label | I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | ... | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.0 | 0.625800 | 1.058373 | 0.000000 | 1.217181 | 0.000000 | 0.000000 | 0.920250 | 0.000000 | ... | 8 | 66 | 0 | 0 | 3 | 0 | 1 | 96 | 0 | 0 |
| 1 | 0 | 0.0 | -1.000000 | 0.869294 | 0.925237 | 1.231491 | 1.055658 | 0.423036 | 0.925237 | 1.031488 | ... | 7 | 52 | 0 | 0 | 47 | 0 | 7 | 112 | 0 | 0 |
| 2 | 0 | 0.0 | 0.000000 | 0.554618 | 0.820286 | 1.148252 | 1.032922 | 0.732569 | 0.925237 | 1.092790 | ... | 8 | 49 | 0 | 0 | 25 | 0 | 6 | 53 | 0 | 0 |
| 3 | 0 | 0.0 | 0.829305 | 0.423036 | 0.672503 | 1.215852 | 1.044182 | 0.706395 | 0.672503 | 0.909015 | ... | 8 | 37 | 0 | 0 | 156 | 0 | 0 | 32 | 0 | 0 |
| 4 | 0 | 0.0 | 0.000000 | 1.005164 | 0.902628 | 1.147829 | 1.024444 | 0.672503 | 0.917610 | 0.929876 | ... | 8 | 14 | 5 | 3 | 9 | 0 | 0 | 5 | 1 | 47 |
5 rows × 40 columns
train_data.shape(200, 40)三、特征表示的统一
看过DeepCTR源码的人可能就会知道,项目中输入分成三大类,分别是SparseFeat, DenseFeat, VarLenSparseFeat,并且使用类进行了封装,其中也考虑到效率的问题做了一些优化,这里不说具体的类的实现及优化是什么,我先来思考一下使用这三类特征可以表示大多数推荐场景下的特征嘛?
SparseFeat: 稀疏特征的标记,一般是用来表示id类特征
DenseFeat: 表示数值型特征,可以是一维的也可以是多维的
VarLenSparseFeat: 可变长的id类特征,就是id序列特征
这三类特征在实际的推荐系统应用中包含了绝大多数的特征类型,在石塔西大佬的推荐算法的”五环之歌”中也说到,类别特征才是推荐系统中的一等公民,也就是说大部分的特征都是类别特征,也可能会有一些其他的比如图像、视频等其它特征,虽然实际存不存在,但是我感觉如果要是用这些特征就需要将其转换成向量的形式去使用,也就是DenseFeat多维度的情况。
那么有了这三个统一的标志有什么用呢?答案是用来更好的构建输入层!
SparseFeat
SparseFeat is a namedtuple with signature SparseFeat(name, vocabulary_size, embedding_dim, use_hash, dtype, embeddings_initializer, embedding_name, group_name, trainable)- name : feature name
- vocabulary_size : number of unique feature values for sprase feature or hashing space when
use_hash=True - embedding_dim : embedding dimension
- use_hash : defualt
False.IfTruethe input will be hashed to space of sizevocabulary_size. - dtype : default
int32.dtype of input tensor. - embeddings_initializer : initializer for the
embeddingsmatrix. - embedding_name : default
None. If None, the embedding_name will be same asname. - group_name : feature group of this feature.
- trainable: default
True.Whether or not the embedding is trainable.
DenseFeat
DenseFeat is a namedtuple with signature DenseFeat(name, dimension, dtype, transform_fn)- name : feature name
- dimension : dimension of dense feature vector.
- dtype : default
float32.dtype of input tensor. - transform_fn : If not
None, a function that can be used to transform values of the feature. the function takes the input Tensor as its argument, and returns the output Tensor. (e.g.lambda x: (x - 3.0) / 4.2).
VarLenSparseFeat
VarLenSparseFeat is a namedtuple with signature VarLenSparseFeat(sparsefeat, maxlen, combiner, length_name, weight_name,weight_norm)- sparsefeat : a instance of
SparseFeat - maxlen : maximum length of this feature for all samples
- combiner : pooling method,can be
sum,meanormax - length_name : feature length name,if
None, value 0 in feature is for padding. - weight_name : default
None. If not None, the sequence feature will be multiplyed by the feature whose name isweight_name. - weight_norm : default
True. Whether normalize the weight score or not.
# 对特征做标记,并确定 vocabulary_size、embedding,注意 SpareFeat 和 DenseFeat 不同
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),\
embedding_dim=4) for feat in sparse_features]+\
[DenseFeat(feat, 1) for feat in dense_features]
print(dnn_feature_columns[1])
len(dnn_feature_columns),type(dnn_feature_columns),type(dnn_feature_columns[1])SparseFeat(name='C2', vocabulary_size=92, embedding_dim=4, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x0000027092099520>, embedding_name='C2', group_name='default_group', trainable=True)(39, list, deepctr.feature_column.SparseFeat)Explain
- for C26 example, vocabulary_size 90 means data[“C26”] unique numbers.
SparseFeat(name='C26', vocabulary_size=90, embedding_dim=4, use_hash=False, dtype='int32', embeddings_initializer=<tensorflow.python.keras.initializers.initializers_v1.RandomNormal object at 0x000001F64210D040>, embedding_name='C26', group_name='default_group', trainable=True)# test
train_data[train_data["C26"] == 89]| label | I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | ... | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 121 | 1 | 0.554618 | 0.423036 | 0.869294 | 0.87437 | 0.423036 | 0.87437 | 0.554618 | 0.837467 | 0.87437 | ... | 0 | 64 | 28 | 1 | 94 | 0 | 0 | 12 | 16 | 89 |
1 rows × 40 columns
四、构建多输入模型
先说答案:将输入的数据转换成字典的形式,定义输入层的时候让输入层的name和字典中特征的key一致,就可以使得输入的数据和对应的Input层对应,后面搭建模型就是和上面介绍的一样的了。
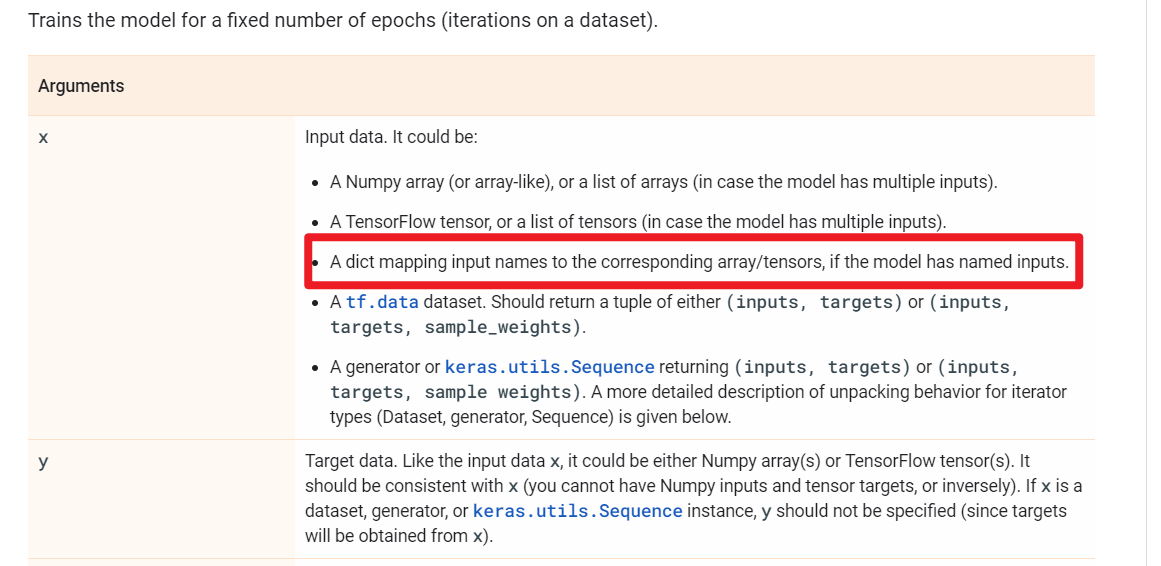
直接看个例子:
from keras.models import Model
from keras.layers import *
from keras.utils import plot_model
import numpy as np
# 定义三维特征
x = {'f1': np.random.random((5,1)),
'f2': np.random.random((5,1)),
'f3': np.random.random((5,1))}
y = np.array([0, 1, 0, 1, 1])
# 定义输入层:这里层的名称和特征的名称是相同的,所以在模型训练的时候直接输入这个
# 字典形式的数据就可以
inputs = [Input(shape=(1, ), name=key) for key, _ in x.items()]
# 将多个输入拼接之后,在经过一个Dense层输出
concat_feat = Concatenate(axis=1)(inputs)
# 将输入特征映射成1维
output = Dense(1, activation='sigmoid')(concat_feat)
# 构建模型
model = Model(inputs, output)
model.summary()
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics='acc')
# 模型训练和验证
model.fit(x, y, batch_size=1, epochs=2, validation_split=0.2)
# 将模型的结构画出来
keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True)
上面就是举了个简单的例子说明,当多输入特别多的时候,构建模型我们可以将数据转换成字典的形式,然后字典中特征的名称与其对应的Input层的名称一致就行,这里是为了后面搭建复杂模型打基础。
五、通过特征标记构造输入层
在前面的函数式API构建模型最后说到过,可以使用字典的形式构建输入,最后只要将对应Input层的名字与字典中特征的key相对应就可以。在定义Input层的时候,除了name以外还有一个重要的属性就是shape
然而所有特征Input层的shape其实只有4种情况:
- 数值特征,1维的数值特征shape=(1, )
- 多维的数值特征shape=(dimension, )
- 类别特征,shape=(1,), 为什么类别特征的shape维度是1呢,因为输入的就是一个id,在类别型特征的Input后面还需要接一个Embedding层,将id转化成稠密的向量
- 可变长的序列特征,shape=(maxlen, 1), 序列的输入往往需要定义一个最大长度,这样不至于序列长度之间相差太大,这个最大长度可以是实际数据中的最大长度,也可以是根据经验定义的最大长度。需要注意的是,序列特征中的每个元素其实也是一个id类特征,在最后转换成Embedding的时候,不是一个Embedding向量,而是一个矩阵。
上面说了Input层的四种情况有什么用呢?
当特征维度特别多的时候,比如成百上千维特征,如果没有这种标记的话,我们就需要挨个定义每个特征对应的Input层,当然有人可能会说可以提前分组然后再给不同的Input层,其实本质上是一样的。
# 构建输入层
def build_input_layers(feature_columns):
dense_input_dict, sparse_input_dict = {},{}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
# DenseFeat(name='I1', dimension=1, dtype='float32', transform_fn=None)
elif isinstance(fc, DenseFeat):
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
return dense_input_dict, sparse_input_dict
dense_input_dict, sparse_input_dict = build_input_layers(dnn_feature_columns)
print(dense_input_dict["I1"])
print(sparse_input_dict["C1"])KerasTensor(type_spec=TensorSpec(shape=(None, 1), dtype=tf.float32, name='I1'), name='I1', description="created by layer 'I1'")
KerasTensor(type_spec=TensorSpec(shape=(None, 1), dtype=tf.float32, name='C1'), name='C1', description="created by layer 'C1'")input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
type(input_layers),len(input_layers),input_layers[0](list,
39,
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'I1')>)六、Embedding Layer
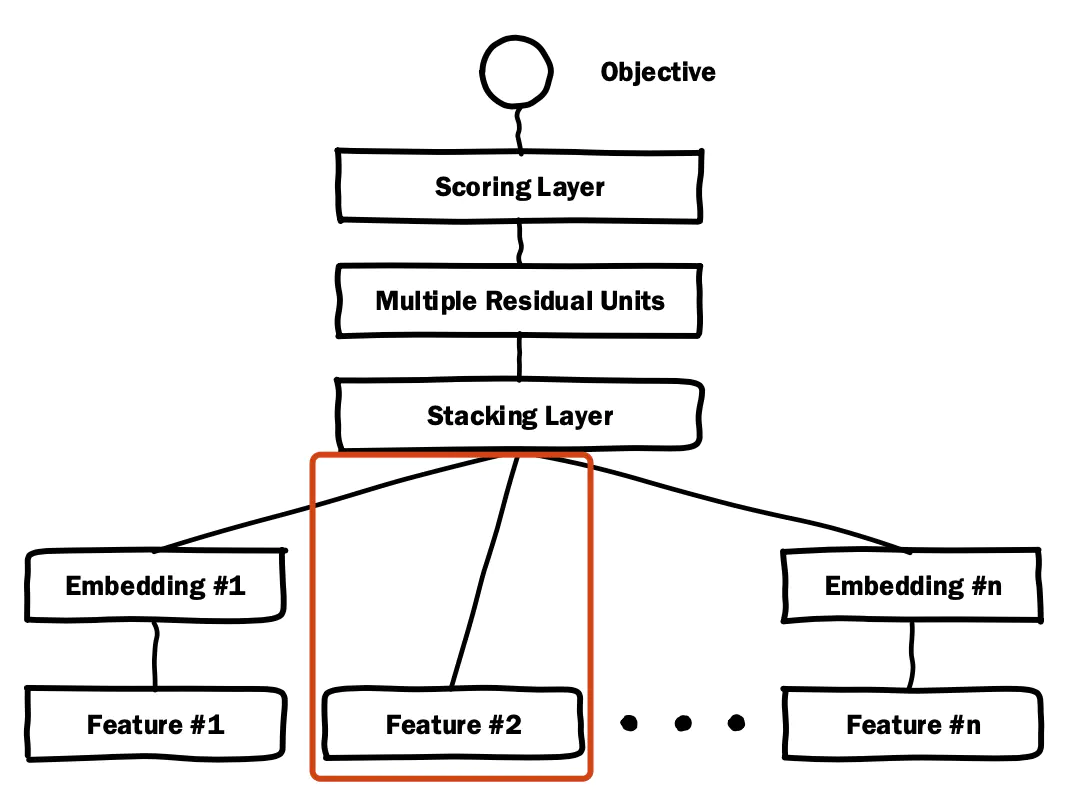
将稀疏的类别型特征转成稠密的Embedding向量,Embedding的维度会远小于原始的稀疏特征向量。 Embedding是NLP里面常用的一种技术,这里的Feature #1表示的类别特征(one-hot编码后的稀疏特征向量), Feature #2是数值型特征,不用embedding, 直接到了Stacking Layer。关于Embedding Layer的实现, 往往一个全连接层即可,Tensorflow中有实现好的层可以直接用。和NLP里面的embedding技术异曲同工, 比如Word2Vec, 语言模型等。
Python3 filter() 函数
描述
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
语法
以下是 filter() 方法的语法:
filter(function, iterable)参数
- function — 判断函数。
- iterable — 可迭代对象。
返回值
返回一个迭代器对象
实例
以下展示了使用 filter 函数的实例:
过滤出列表中的所有奇数:
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
newlist = list(tmplist)
print(newlist)输出结果 :
[1, 3, 5, 7, 9]# 将所有的 dense 进行 embedding 操作
def build_embedding_layers(feature_columns, is_linear):
embedding_layers_dict = {}
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
if is_linear:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size+1,1,name="1d_emb_"+fc.name)
# SparseFeat(name='C26', vocabulary_size=90, embedding_dim=4, use_hash=False,
# dtype='int32', embedding_name='C26', group_name='default_group', trainable=True)
else:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size+1, fc.embedding_dim, name="kd_emb_"+fc.name)
return embedding_layers_dictembedding_layer_dict = build_embedding_layers(dnn_feature_columns,is_linear=False)
embedding_layer_dict["C1"]<tensorflow.python.keras.layers.embeddings.Embedding at 0x270ae3209d0>七、Stacking Layer
这个层是把不同的Embedding特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量,该层通常也称为连接层, 具体的实现如下,先将所有的数值特征拼接起来,然后将所有的Embedding拼接起来,最后将数值特征和Embedding特征拼接起来作为DNN的输入,这里TF是通过Concatnate层进行拼接。
# 将所有的 sparse 特征 embedding 拼接
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=True):
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
embedding_list = []
for fc in sparse_feature_columns:
_input = input_layer_dict[fc.name]
_embed = embedding_layer_dict[fc.name]
embed = _embed(_input)
if flatten:
embed = Flatten()(embed)
embedding_list.append(embed)
return embedding_list# 拼接所有的 dense
dense_dnn_list = list(dense_input_dict.values())
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list)
print(dense_dnn_inputs)
print(len(dense_dnn_list),type(dense_dnn_inputs))KerasTensor(type_spec=TensorSpec(shape=(None, 13), dtype=tf.float32, name=None), name='concatenate_6/concat:0', description="created by layer 'concatenate_6'")
13 <class 'tensorflow.python.keras.engine.keras_tensor.KerasTensor'># 拼接所有的 sparse
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list)
print(sparse_dnn_inputs)
print(len(sparse_dnn_list),type(sparse_dnn_inputs))KerasTensor(type_spec=TensorSpec(shape=(None, 104), dtype=tf.float32, name=None), name='concatenate_7/concat:0', description="created by layer 'concatenate_7'")
26 <class 'tensorflow.python.keras.engine.keras_tensor.KerasTensor'>dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs])
dnn_inputs<KerasTensor: shape=(None, 117) dtype=float32 (created by layer 'concatenate_11')>八、Multiple Residual Units Layer
该层的主要结构是MLP, 但DeepCrossing采用了残差网络进行的连接。通过多层残差网络对特征向量各个维度充分的交叉组合, 使得模型能够抓取更多的非线性特征和组合特征信息, 增加模型的表达能力。
Deep Crossing模型使用稍微修改过的残差单元,它不使用卷积内核,改为了两层神经网络。我们可以看到,残差单元是通过两层ReLU变换再将原输入特征相加回来实现的。
# units: 64
# out_dim: 117
# inputs: Tensor("Placeholder:0", shape=(None, 117), dtype=float32)
# dnn1: Tensor("residual_block_6/dense/Relu:0", shape=(None, 64), dtype=float32)
# dnn2: Tensor("residual_block_6/dense_1/Relu:0", shape=(None, 117), dtype=float32)
# units: 64
# out_dim: 117
# inputs: Tensor("Placeholder:0", shape=(None, 117), dtype=float32)
# dnn1: Tensor("residual_block_7/dense/Relu:0", shape=(None, 64), dtype=float32)
# dnn2: Tensor("residual_block_7/dense_1/Relu:0", shape=(None, 117), dtype=float32)
class ResidualBlock(Layer):
def __init__(self, units):
super(ResidualBlock, self).__init__()
self.units = units
# print("units: ",self.units)
def build(self, input_shape):
out_dim = input_shape[-1]
# print("out_dim: ",out_dim)
self.dnn1 = Dense(self.units, activation="relu")
self.dnn2 = Dense(out_dim, activation="relu")
def call(self, inputs):
# print("inputs: ",inputs)
x = inputs
x = self.dnn1(x)
# print("dnn1:",x)
x = self.dnn2(x)
# print("dnn2:",x)
x = Activation("relu")(x + inputs)
return x九、Scoring Layer
这个作为输出层,为了拟合优化目标存在。 对于CTR预估二分类问题, Scoring往往采用逻辑回归,模型通过叠加多个残差块加深网络的深度,最后将结果转换成一个概率值输出。
def get_dnn_logits(dnn_inputs, block_nums=3):
dnn_out = dnn_inputs
for i in range(block_nums):
dnn_out = ResidualBlock(64)(dnn_out)
dnn_logits = Dense(1, activation="sigmoid")(dnn_out)
return dnn_logits从模型的代码结构上来看,DeepCrossing的模型输入主要由数值特征和类别特征组成,并将经过Embedding之后的类别特征及类别特征拼接在一起,详细的拼接代码如Staking Layer所示,下面是构建模型的核心代码
def DeepCrossing(dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(dnn_feature_columns)
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, is_linear=False)
# 拼接所有的 dense 特征
# dense_dnn_list: <KerasTensor: shape=(None, 13) dtype=float32 >
dense_dnn_list = list(dense_input_dict.values())
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list)# B x n (n表示数值特征的数量13)
# 拼接所有的 sparse 特征,需要 Flatten
# sparse_dnn_inputs: <KerasTensor: shape=(None, 104) dtype=float32>
# 26(C1-C26) * 4(fc.embedding_dim=4) = 104
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list)
# 拼接 dense & sparse (None, 104+13)
# dnn_inputs:<KerasTensor: shape=(None, 117) dtype=float32>
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs])
output_layer = get_dnn_logits(dnn_inputs, block_nums=3)
model = Model(input_layers, output_layer)
return modelhistory = DeepCrossing(dnn_feature_columns)
history.summary()Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
C1 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C2 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C3 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C4 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C5 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C6 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C7 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C8 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C9 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C10 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C11 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C12 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C13 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C14 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C15 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C16 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C17 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C18 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C19 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C20 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C21 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C22 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C23 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C24 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C25 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
C26 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
kd_emb_C1 (Embedding) (None, 1, 4) 112 C1[0][0]
__________________________________________________________________________________________________
kd_emb_C2 (Embedding) (None, 1, 4) 372 C2[0][0]
__________________________________________________________________________________________________
kd_emb_C3 (Embedding) (None, 1, 4) 692 C3[0][0]
__________________________________________________________________________________________________
kd_emb_C4 (Embedding) (None, 1, 4) 632 C4[0][0]
__________________________________________________________________________________________________
kd_emb_C5 (Embedding) (None, 1, 4) 52 C5[0][0]
__________________________________________________________________________________________________
kd_emb_C6 (Embedding) (None, 1, 4) 32 C6[0][0]
__________________________________________________________________________________________________
kd_emb_C7 (Embedding) (None, 1, 4) 736 C7[0][0]
__________________________________________________________________________________________________
kd_emb_C8 (Embedding) (None, 1, 4) 80 C8[0][0]
__________________________________________________________________________________________________
kd_emb_C9 (Embedding) (None, 1, 4) 12 C9[0][0]
__________________________________________________________________________________________________
kd_emb_C10 (Embedding) (None, 1, 4) 572 C10[0][0]
__________________________________________________________________________________________________
kd_emb_C11 (Embedding) (None, 1, 4) 696 C11[0][0]
__________________________________________________________________________________________________
kd_emb_C12 (Embedding) (None, 1, 4) 684 C12[0][0]
__________________________________________________________________________________________________
kd_emb_C13 (Embedding) (None, 1, 4) 668 C13[0][0]
__________________________________________________________________________________________________
kd_emb_C14 (Embedding) (None, 1, 4) 60 C14[0][0]
__________________________________________________________________________________________________
kd_emb_C15 (Embedding) (None, 1, 4) 684 C15[0][0]
__________________________________________________________________________________________________
kd_emb_C16 (Embedding) (None, 1, 4) 676 C16[0][0]
__________________________________________________________________________________________________
kd_emb_C17 (Embedding) (None, 1, 4) 40 C17[0][0]
__________________________________________________________________________________________________
kd_emb_C18 (Embedding) (None, 1, 4) 512 C18[0][0]
__________________________________________________________________________________________________
kd_emb_C19 (Embedding) (None, 1, 4) 180 C19[0][0]
__________________________________________________________________________________________________
kd_emb_C20 (Embedding) (None, 1, 4) 20 C20[0][0]
__________________________________________________________________________________________________
kd_emb_C21 (Embedding) (None, 1, 4) 680 C21[0][0]
__________________________________________________________________________________________________
kd_emb_C22 (Embedding) (None, 1, 4) 28 C22[0][0]
__________________________________________________________________________________________________
kd_emb_C23 (Embedding) (None, 1, 4) 44 C23[0][0]
__________________________________________________________________________________________________
kd_emb_C24 (Embedding) (None, 1, 4) 504 C24[0][0]
__________________________________________________________________________________________________
kd_emb_C25 (Embedding) (None, 1, 4) 84 C25[0][0]
__________________________________________________________________________________________________
kd_emb_C26 (Embedding) (None, 1, 4) 364 C26[0][0]
__________________________________________________________________________________________________
I1 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I2 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I3 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I4 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I5 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I6 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I7 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I8 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I9 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I10 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I11 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I12 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
I13 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
flatten_78 (Flatten) (None, 4) 0 kd_emb_C1[0][0]
__________________________________________________________________________________________________
flatten_79 (Flatten) (None, 4) 0 kd_emb_C2[0][0]
__________________________________________________________________________________________________
flatten_80 (Flatten) (None, 4) 0 kd_emb_C3[0][0]
__________________________________________________________________________________________________
flatten_81 (Flatten) (None, 4) 0 kd_emb_C4[0][0]
__________________________________________________________________________________________________
flatten_82 (Flatten) (None, 4) 0 kd_emb_C5[0][0]
__________________________________________________________________________________________________
flatten_83 (Flatten) (None, 4) 0 kd_emb_C6[0][0]
__________________________________________________________________________________________________
flatten_84 (Flatten) (None, 4) 0 kd_emb_C7[0][0]
__________________________________________________________________________________________________
flatten_85 (Flatten) (None, 4) 0 kd_emb_C8[0][0]
__________________________________________________________________________________________________
flatten_86 (Flatten) (None, 4) 0 kd_emb_C9[0][0]
__________________________________________________________________________________________________
flatten_87 (Flatten) (None, 4) 0 kd_emb_C10[0][0]
__________________________________________________________________________________________________
flatten_88 (Flatten) (None, 4) 0 kd_emb_C11[0][0]
__________________________________________________________________________________________________
flatten_89 (Flatten) (None, 4) 0 kd_emb_C12[0][0]
__________________________________________________________________________________________________
flatten_90 (Flatten) (None, 4) 0 kd_emb_C13[0][0]
__________________________________________________________________________________________________
flatten_91 (Flatten) (None, 4) 0 kd_emb_C14[0][0]
__________________________________________________________________________________________________
flatten_92 (Flatten) (None, 4) 0 kd_emb_C15[0][0]
__________________________________________________________________________________________________
flatten_93 (Flatten) (None, 4) 0 kd_emb_C16[0][0]
__________________________________________________________________________________________________
flatten_94 (Flatten) (None, 4) 0 kd_emb_C17[0][0]
__________________________________________________________________________________________________
flatten_95 (Flatten) (None, 4) 0 kd_emb_C18[0][0]
__________________________________________________________________________________________________
flatten_96 (Flatten) (None, 4) 0 kd_emb_C19[0][0]
__________________________________________________________________________________________________
flatten_97 (Flatten) (None, 4) 0 kd_emb_C20[0][0]
__________________________________________________________________________________________________
flatten_98 (Flatten) (None, 4) 0 kd_emb_C21[0][0]
__________________________________________________________________________________________________
flatten_99 (Flatten) (None, 4) 0 kd_emb_C22[0][0]
__________________________________________________________________________________________________
flatten_100 (Flatten) (None, 4) 0 kd_emb_C23[0][0]
__________________________________________________________________________________________________
flatten_101 (Flatten) (None, 4) 0 kd_emb_C24[0][0]
__________________________________________________________________________________________________
flatten_102 (Flatten) (None, 4) 0 kd_emb_C25[0][0]
__________________________________________________________________________________________________
flatten_103 (Flatten) (None, 4) 0 kd_emb_C26[0][0]
__________________________________________________________________________________________________
concatenate_12 (Concatenate) (None, 13) 0 I1[0][0]
I2[0][0]
I3[0][0]
I4[0][0]
I5[0][0]
I6[0][0]
I7[0][0]
I8[0][0]
I9[0][0]
I10[0][0]
I11[0][0]
I12[0][0]
I13[0][0]
__________________________________________________________________________________________________
concatenate_13 (Concatenate) (None, 104) 0 flatten_78[0][0]
flatten_79[0][0]
flatten_80[0][0]
flatten_81[0][0]
flatten_82[0][0]
flatten_83[0][0]
flatten_84[0][0]
flatten_85[0][0]
flatten_86[0][0]
flatten_87[0][0]
flatten_88[0][0]
flatten_89[0][0]
flatten_90[0][0]
flatten_91[0][0]
flatten_92[0][0]
flatten_93[0][0]
flatten_94[0][0]
flatten_95[0][0]
flatten_96[0][0]
flatten_97[0][0]
flatten_98[0][0]
flatten_99[0][0]
flatten_100[0][0]
flatten_101[0][0]
flatten_102[0][0]
flatten_103[0][0]
__________________________________________________________________________________________________
concatenate_14 (Concatenate) (None, 117) 0 concatenate_12[0][0]
concatenate_13[0][0]
__________________________________________________________________________________________________
residual_block (ResidualBlock) (None, 117) 15157 concatenate_14[0][0]
__________________________________________________________________________________________________
residual_block_1 (ResidualBlock (None, 117) 15157 residual_block[0][0]
__________________________________________________________________________________________________
residual_block_2 (ResidualBlock (None, 117) 15157 residual_block_1[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1) 118 residual_block_2[0][0]
==================================================================================================
Total params: 54,805
Trainable params: 54,805
Non-trainable params: 0
__________________________________________________________________________________________________history.compile(optimizer="adam",loss="binary_crossentropy",metrics=["binary_crossentropy"\
, tf.keras.metrics.AUC(name="auc")])train_model_input = {name: data[name] for name in dense_features + sparse_features}
history.fit(train_model_input, train_data["label"].values, batch_size=128, epochs=10,validation_split=0.2)Epoch 1/10
2/2 [==============================] - 4s 622ms/step - loss: 0.8003 - binary_crossentropy: 0.8003 - auc: 0.4711 - val_loss: 0.6696 - val_binary_crossentropy: 0.6696 - val_auc: 0.4744
Epoch 2/10
2/2 [==============================] - 0s 70ms/step - loss: 0.6390 - binary_crossentropy: 0.6390 - auc: 0.4995 - val_loss: 0.6319 - val_binary_crossentropy: 0.6319 - val_auc: 0.5285
Epoch 3/10
2/2 [==============================] - 0s 70ms/step - loss: 0.5572 - binary_crossentropy: 0.5572 - auc: 0.5066 - val_loss: 0.6401 - val_binary_crossentropy: 0.6401 - val_auc: 0.5427
Epoch 4/10
2/2 [==============================] - 0s 70ms/step - loss: 0.5400 - binary_crossentropy: 0.5400 - auc: 0.5880 - val_loss: 0.6674 - val_binary_crossentropy: 0.6674 - val_auc: 0.5855
Epoch 5/10
2/2 [==============================] - 0s 69ms/step - loss: 0.5422 - binary_crossentropy: 0.5422 - auc: 0.5959 - val_loss: 0.6974 - val_binary_crossentropy: 0.6974 - val_auc: 0.6140
Epoch 6/10
2/2 [==============================] - 0s 72ms/step - loss: 0.5431 - binary_crossentropy: 0.5431 - auc: 0.6414 - val_loss: 0.7074 - val_binary_crossentropy: 0.7074 - val_auc: 0.6510
Epoch 7/10
2/2 [==============================] - 0s 70ms/step - loss: 0.5186 - binary_crossentropy: 0.5186 - auc: 0.7036 - val_loss: 0.6900 - val_binary_crossentropy: 0.6900 - val_auc: 0.6909
Epoch 8/10
2/2 [==============================] - 0s 70ms/step - loss: 0.5130 - binary_crossentropy: 0.5130 - auc: 0.7707 - val_loss: 0.6581 - val_binary_crossentropy: 0.6581 - val_auc: 0.7350
Epoch 9/10
2/2 [==============================] - 0s 71ms/step - loss: 0.5084 - binary_crossentropy: 0.5084 - auc: 0.8042 - val_loss: 0.6325 - val_binary_crossentropy: 0.6325 - val_auc: 0.7393
Epoch 10/10
2/2 [==============================] - 0s 69ms/step - loss: 0.4865 - binary_crossentropy: 0.4865 - auc: 0.8240 - val_loss: 0.6163 - val_binary_crossentropy: 0.6163 - val_auc: 0.7479<tensorflow.python.keras.callbacks.History at 0x270be4a3730>疑问
模型训练时,助教代码给的是使用 data 数据集,但我一直认为 data 并没有被改变,还是原来读取初始数据的变量,但是并不影响运行,于是我进行了两步判断,输出 data 结果;其次判断 data 和 train_data 是否相同。验证结果如下。
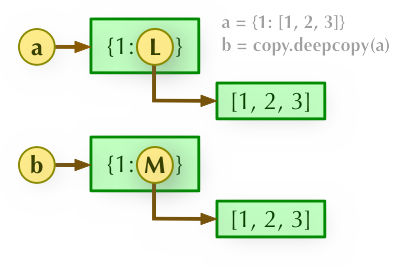
Python 直接赋值、浅拷贝和深度拷贝解析
- 直接赋值:其实就是对象的引用(别名)。
- 浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
字典浅拷贝实例
实例
>>>a = {1: [1,2,3]}
>>> b = a.copy()
>>> a, b
({1: [1, 2, 3]}, {1: [1, 2, 3]})
>>> a[1].append(4)
>>> a, b
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})深度拷贝需要引入 copy 模块:
实例
>>>import copy
>>> c = copy.deepcopy(a)
>>> a, c
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})
>>> a[1].append(5)
>>> a, c
({1: [1, 2, 3, 4, 5]}, {1: [1, 2, 3, 4]})解析
1、b = a: 赋值引用,a 和 b 都指向同一个对象。
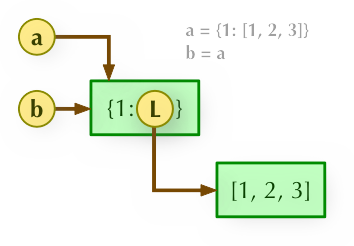
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
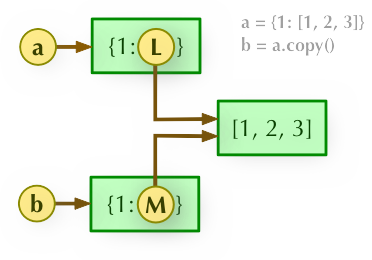
3、b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
# 可以发现当前的 data 数据值已经被改变
data.head()| label | I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | ... | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.0 | 0.625800 | 1.058373 | 0.000000 | 1.217181 | 0.000000 | 0.000000 | 0.920250 | 0.000000 | ... | 8 | 66 | 0 | 0 | 3 | 0 | 1 | 96 | 0 | 0 |
| 1 | 0 | 0.0 | -1.000000 | 0.869294 | 0.925237 | 1.231491 | 1.055658 | 0.423036 | 0.925237 | 1.031488 | ... | 7 | 52 | 0 | 0 | 47 | 0 | 7 | 112 | 0 | 0 |
| 2 | 0 | 0.0 | 0.000000 | 0.554618 | 0.820286 | 1.148252 | 1.032922 | 0.732569 | 0.925237 | 1.092790 | ... | 8 | 49 | 0 | 0 | 25 | 0 | 6 | 53 | 0 | 0 |
| 3 | 0 | 0.0 | 0.829305 | 0.423036 | 0.672503 | 1.215852 | 1.044182 | 0.706395 | 0.672503 | 0.909015 | ... | 8 | 37 | 0 | 0 | 156 | 0 | 0 | 32 | 0 | 0 |
| 4 | 0 | 0.0 | 0.000000 | 1.005164 | 0.902628 | 1.147829 | 1.024444 | 0.672503 | 0.917610 | 0.929876 | ... | 8 | 14 | 5 | 3 | 9 | 0 | 0 | 5 | 1 | 47 |
5 rows × 40 columns
# 检验两者是否相同,结果为 True
data is train_dataTrue参考资料
- DeepCrossing
- AI算法工程师手册
- deepctr
- 论文原文
- 无中生有:论推荐算法中的Embedding思想
- AI上推荐 之 AutoRec与Deep Crossing模型(改变神经网络的复杂程度)
- embedding层和全连接层的区别是什么?
- What is the difference between embeddings and pca?
- What is the connection between PCA and Word2Vec in terms of word embedding? Is there an empiric superiority between the two?



