相关资料汇总
背景知识
1.交易日
每年交易日并不是 365 或者 366,而是 253 左右。
在业务中,交易日或常规交易时间(RTH) 是特定证券交易所开放的时间跨度,而不是电子或延长交易时间(ETH)。例如,纽约证券交易所是,截至2020年,从上午9点开美国东部时间到下午4:00东部时间。交易日通常是星期一至星期五。交易日结束时,所有股票交易结束,并冻结时间,直到下一个交易日开始。还有其他几种特殊情况会导致交易日缩短,或者根本没有交易日,例如节假日或国葬日。一的国家元首是如期举行。
纽约证券交易所和纳斯达克平均每年约253个交易日。这是从365.25(平均每年的天数) 5/7(每周的比例工作日)-6(工作日假日)-3 5/7(固定日期假日)= 252.75≈253。股票交易所的假日元旦,小马丁·路德·金纪念日,华盛顿诞辰,耶稣受难日,阵亡将士纪念日,独立日),劳动节,感恩节和圣诞节关闭;还有一些允许交易的假期,包括哥伦布日,退伍军人节和除夕。[1]最多可以缩短三个交易日(独立日之前的一天,感恩节之后的一天)以及圣诞节前夕),即交易所的开放时间为上午9:30 –下午1:00,具体取决于日历年的交易地点。
数据大概 500 天,也就是两年的数据信息
2.Investment Time Horizon
长线投资和短线投资的区别和特点
数学支撑
1.峰度(Kurtosis)与偏态(Skewness)
(1)偏度(Skewness)
偏度衡量随机变量概率分布的不对称性,是相对于平均值不对称程度的度量,通过对偏度系数的测量,我们能够判定数据分布的不对称程度以及方向。
具体来说,对于随机变量X,我们定义偏度为其的三阶标准中心距:
对于样本的偏度,我们一般记为SK,我们可以基于矩估计,得到有:
其中, 为样本均值,
为样本三阶中心矩,
为样本二阶中心矩
偏度的衡量是相对于正态分布来说,正态分布的偏度为0,即若数据分布是对称的,偏度为0。若偏度大于0,则分布右偏,即分布有一条长尾在右;若偏度小于0,则分布为左偏,即分布有一条长尾在左(如下图);同时偏度的绝对值越大,说明分布的偏移程度越严重。
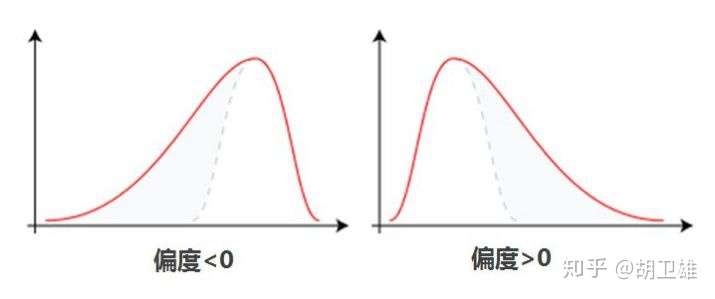
【注意】数据分布的左偏或右偏,指的是数值拖尾的方向,而不是峰的位置。
(2)峰度(Kurtosis)
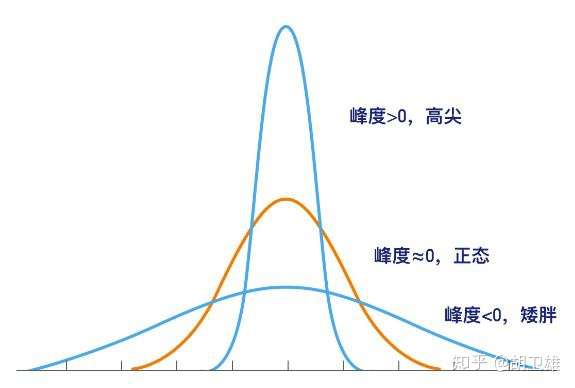
峰度,是研究数据分布陡峭或者平滑的统计量,通过对峰度系数的测量,我们能够判定数据相对于正态分布而言是更陡峭还是更平缓。比如正态分布的峰度为0,均匀分布的峰度为-1.2(平缓),指数分布的峰度6(陡峭)。
峰度,定义为四阶中心距 除以方差
的平方减3。
若峰度 0 , 分布的峰态服从正态分布;
若峰度>0,分布的峰态陡峭(高尖);
若峰度<0,分布的峰态平缓(矮胖);
2.核密度估计(kernel density estimation)
pandas.DataFrame.plot.kde
DataFrame.plot.kde(bw_method=None, ind=None, **kwargs)[source]
Generate Kernel Density Estimate plot using Gaussian kernels.
In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function (PDF) of a random variable. This function uses Gaussian kernels and includes automatic bandwidth determination.
核密度估计(kernel density estimation)
Table of Contents
有一些数据,想“看看”它长什么样,我们一般会画直方图(Histogram)。现在你也可以用核密度估计。
什么是“核”
如果不了解背景,看到“核密度估计”这个概念基本上就是一脸懵逼。我们先说说这个核 (kernel)) 是什么。
首先,“核”在不同的语境下的含义是不同的,例如在模式识别里,它的含义就和这里不同。在“非参数估计”的语境下,“核”是一个函数,用来提供权重。例如高斯函数 (Gaussian) 就是一个常用的核函数。
让我们举个例子,假设我们现在想买房,钱不够要找亲戚朋友借,我们用一个数组来表示 5 个亲戚的财产状况: [8, 2, 5, 6, 4]。我们是中间这个数 5。“核”可以类比 成朋友圈,但不同的亲戚朋友亲疏有别,在借钱的时候,关系好的朋友出力多,关系不好的朋友出力少,于是我们可以用权重来表示。总共能借到的钱是: 8*0.1 + 2*0.4 + 5 + 6*0.3 + 4*0.2 = 9.2。
那么“核”的作用就是用来决定权重,例如高斯函数(即正态分布):

如果还套用上面的例子的话,可以认为在 3 代血亲之外的亲戚就基本不会借钱给你了。
博客
Kaggle Jane Street 市场预测数据竞赛1月回顾
特征(feature)和标签(tag)的含义:
由于我们得到的数据都是经过处理的而不是原始数据,这让特征之间的关系模糊甚至消失。以下内容大部分是相对可靠的,而含有(*)的相关内容,是相对不确定,仅供参考。
- feature 0: 卖/买
二元取值,1和-1(而不是1和0)各佔大约一半。 - tag 22: 交易日时间(可能经过处理)
feature_64只有一个tag,就是tag_22.
- feature 0: 卖/买
tag 14: 特定股票数据(沽空成本,股息率,隐含波动率?)
tag 14的特征(feature 41-43)都是成组出现的。(下图date 12的数据)
可能有用的trick
- 去除前85天的数据
- 去除weight为0的数据
- 用所有resp来训练模型
- 给训练集设置权重
量化投资学习笔记93——Kaggle量化交易竞赛Jane Street 笔记2
Kaggle Notebook
Blending tensorflow and pytorch🔥🔥🔥
目前开源最高分数,使用的 tensorflow 和 pytorch
训练 link Pytorch Resnet Starter[Training]
Jane Street: Neural Network Starter
Idea
数据划分
- 5个resp (resp,resp_1,resp_2,resp_3,resp_4)
这四个 resp (resp_1,resp_2,resp_3,resp_4),推测是由一些特征组合算出来的,应当利用 feature 和 tag,将特征划分成4或5份。其中5份并不是很推荐,因为我偏向于resp 是基于resp_1~resp_2组合加权得到的。
- feature_{0…129}
可以做的分析,一定要做特征提取
- PCA 降维
- 去除或者不去相关性很高的 feature
- tag_{0_28}
- 辅助 feature 进行特征提取,核心分块 分4或5



