任务说明
- 任务主题:论文作者统计,统计所有论文作者出现评率Top10的姓名;
- 任务内容:论文作者的统计、使用 Pandas 读取数据并使用字符串操作;
- 任务成果:学习 Pandas 的字符串操作;
数据处理步骤
在原始arxiv数据集中论文作者authors字段是一个字符串格式,其中每个作者使用逗号进行分隔分,所以我们我们首先需要完成以下步骤:
- 使用逗号对作者进行切分;
- 剔除单个作者中非常规的字符;
具体操作可以参考以下例子:
C. Bal\\'azs, E. L. Berger, P. M. Nadolsky, C.-P. Yuan
# 切分为,其中\\为转义符
C. Ba'lazs
E. L. Berger
P. M. Nadolsky
C.-P. Yuan当然在原始数据集中authors_parsed字段已经帮我们处理好了作者信息,可以直接使用该字段完成后续统计。
具体代码实现
一、数据读取
# 导入所需的package
import seaborn as sns #用于画图
from bs4 import BeautifulSoup #用于爬取arxiv的数据
import re #用于正则表达式,匹配字符串的模式
import requests #用于网络连接,发送网络请求,使用域名获取对应信息
import json #读取数据,我们的数据为json格式的
import pandas as pd #数据处理,数据分析
import matplotlib.pyplot as plt #画图工具def readArxivFile(path, columns=['id', 'submitter', 'authors', 'title', 'comments', 'journal-ref', 'doi',
'report-no', 'categories', 'license', 'abstract', 'versions',
'update_date', 'authors_parsed'], count=None):
'''
定义读取文件的函数
path: 文件路径
columns: 需要选择的列
count: 读取行数
'''
data = []
with open(path, 'r') as f:
for idx, line in enumerate(f):
if idx == count:
break
d = json.loads(line)
d = {col : d[col] for col in columns}
data.append(d)
data = pd.DataFrame(data)
return data
data = readArxivFile('../data/arxiv-metadata-oai-snapshot.json',
['id', 'authors', 'categories', 'authors_parsed']
)二、数据统计
接下来我们将对CV领域的论文完成以下统计操作:
- 统计所有作者姓名出现频率的Top10;
- 统计所有作者姓(姓名最后一个单词)的出现频率的Top10;
- 统计所有作者姓第一个字符的评率;
'cs.CV' in data['categories'][1]False# 选择类别为cs.CV下面的论文
data_cv = data[data['categories'].apply(lambda x: 'cs.CV' in x)]
data_cv.head()| id | authors | categories | authors_parsed | |
|---|---|---|---|---|
| 1266 | 0704.1267 | Laurence Likforman-Sulem, Abderrazak Zahour, B... | cs.CV | [[Likforman-Sulem, Laurence, ], [Zahour, Abder... |
| 3634 | 0704.3635 | Fulufhelo Vincent Nelwamondo and Tshilidzi Mar... | cs.CV cs.IR | [[Nelwamondo, Fulufhelo Vincent, ], [Marwala, ... |
| 4201 | 0705.0199 | Erik Berglund, Joaquin Sitte | cs.NE cs.AI cs.CV | [[Berglund, Erik, ], [Sitte, Joaquin, ]] |
| 4216 | 0705.0214 | Mourad Zerai, Maher Moakher | cs.CV | [[Zerai, Mourad, ], [Moakher, Maher, ]] |
| 4451 | 0705.0449 | Pierre-Fran\c{c}ois Marteau (VALORIA), Gilbas ... | cs.CV | [[Marteau, Pierre-François, , VALORIA], [Ménie... |
补充:apply 函数使用
apply 方法常用于 DataFrame 的行迭代或者列迭代,它的 axis 含义与第2小节中的统计聚合函数一致, apply 的参数往往是一个以序列为输入的函数。例如对于 .mean() ,使用 apply 可以如下地写出:
In [88]: df_demo = df[['Height', 'Weight']]
In [89]: def my_mean(x):
....: res = x.mean()
....: return res
....:
In [90]: df_demo.apply(my_mean)
Out[90]:
Height 163.218033
Weight 55.015873
dtype: float64同样的,可以利用 lambda 表达式使得书写简洁,这里的 x 就指代被调用的 df_demo 表中逐个输入的序列:
In [91]: df_demo.apply(lambda x:x.mean())
Out[91]:
Height 163.218033
Weight 55.015873
dtype: float64若指定 axis=1 ,那么每次传入函数的就是行元素组成的 Series ,其结果与之前的逐行均值结果一致。
In [92]: df_demo.apply(lambda x:x.mean(), axis=1).head()
Out[92]:
0 102.45
1 118.25
2 138.95
3 41.00
4 124.00
dtype: float64这里再举一个例子: mad 函数返回的是一个序列中偏离该序列均值的绝对值大小的均值,例如序列1,3,7,10中,均值为5.25,每一个元素偏离的绝对值为4.25,2.25,1.75,4.75,这个偏离序列的均值为3.25。现在利用 apply 计算升高和体重的 mad 指标:
In [93]: df_demo.apply(lambda x:(x-x.mean()).abs().mean())
Out[93]:
Height 6.707229
Weight 10.391870
dtype: float64这与使用内置的 mad 函数计算结果一致:
In [94]: df_demo.mad()
Out[94]:
Height 6.707229
Weight 10.391870
dtype: float64谨慎使用 apply
得益于传入自定义函数的处理,
apply的自由度很高,但这是以性能为代价的。一般而言,使用pandas的内置函数处理和apply来处理同一个任务,其速度会相差较多,因此只有在确实存在自定义需求的情境下才考虑使用apply。
# 查看数据信息type
data_cv['authors_parsed'][1266][['Likforman-Sulem', 'Laurence', ''],
['Zahour', 'Abderrazak', ''],
['Taconet', 'Bruno', '']]data_cv['authors_parsed']1266 [[Likforman-Sulem, Laurence, ], [Zahour, Abder...
3634 [[Nelwamondo, Fulufhelo Vincent, ], [Marwala, ...
4201 [[Berglund, Erik, ], [Sitte, Joaquin, ]]
4216 [[Zerai, Mourad, ], [Moakher, Maher, ]]
4451 [[Marteau, Pierre-François, , VALORIA], [Ménie...
...
1766277 [[Napoletani, D., ], [Struppa, D. C., ], [Saue...
1769100 [[Kouzaev, G. A., ]]
1773553 [[Costa, Luciano da Fontoura, ], [Rocha, Ferna...
1774727 [[Santos, C. Costa, , Univ. Porto], [Bernardes...
1793806 [[Vlasov, Alexander Yu., , FCR/IRH, St.-Peters...
Name: authors_parsed, Length: 48909, dtype: object# 拼接所有作者
all_cv_authors = sum(data_cv['authors_parsed'], [])
all_cv_authors.head()[['Likforman-Sulem', 'Laurence', ''],
['Zahour', 'Abderrazak', ''],
['Taconet', 'Bruno', ''],
['Nelwamondo', 'Fulufhelo Vincent', ''],
['Marwala', 'Tshilidzi', ''],
]补充:sum 函数使用
python内置函数sum(iterable[, start]),当参数iterable为一个二维list,参数start为’[]’,可以达成类似numpy.chararray.flatten的效果。这时候该如何理解sum函数的运行过程呢?
d = [[1,2],[3,4],[5,6]]
sum(d,[])[1, 2, 3, 4, 5, 6]理解思路一
sum(iterable[, start]) 就是求一个可迭代对象(iterable)的和,start 参数是可选的,start 就是求这个和之前的初值。比如,对于一个列表(可迭代对象) li = [1, 2, 3, 4],sum(li) 就等于 10;如果指定一个初值,比如 5,那么 sum(li, 5) 就等于 5 + sum(li),就是 15。对于你的例子,列表 d = [[1, 2], [3, 4], [5, 6]],那么 sum(d) 就是 [1, 2] + [3, 4] + [5, 6],也就是 [1, 2, 3, 4, 5, 6];sum(d, []) 显然就是 [] + [1, 2] + [3, 4] + [5, 6],结果还是 [1, 2, 3, 4, 5, 6];如果你修改第二个参数,变为 sum(d, [9]),那么结果就是 [9, 1, 2, 3, 4, 5, 6]
理解思路二
思路一讲得很对,这边举例详细说明一下。
如下为help(sum)解释
help(sum)Help on built-in function sum in module builtins:
sum(iterable, /, start=0)
Return the sum of a 'start' value (default: 0) plus an iterable of numbers
When the iterable is empty, return the start value.
This function is intended specifically for use with numeric values and may
reject non-numeric types.
主要这句话Return the sum of a ‘start’ value (default: 0) plus an iterable of numbers,简单就是返回起始值start和迭代器每个元素累加的结果,而起始值默认为0。
举例说明:
a=[1,2,3]
sum(a) # 计算结果是sum(a) = 0 + 1 + 2 + 3, 起始start默认为0,是整数,加法没问题
sum(a, start=100) # sum(a, start=100) = 100 + 1 + 2 + 3, start变量也可以人为设置,此时为100,运算没问题
如果是二维list,如[[1,2,3],[4,5,6]], 这时迭代器每个元素均为list,这些元素作加法时start不能再使用默认整数类型值0了,因为整数和list无法做加法运算,即1+[1,2,3]+[4,5,6]运算是错误的,此时需要设置起始变量也为list类型,如start=[],如下:
a=[[1,2,3], [4, 5, 6]]
sum(a) # 这样写是错误的,sum(a) = 0 + [1,2,3] + [4, 5, 6] ,0无法和列表做加法运算
sum(a, start=[]) # 正确, sum(a, []) = [] + [1,2,3] + [4,5,6] = [1,2,3,4,5,6] ,这样才对
sum(a, start=[1,2,3]) # 正确, sum(a, [1,2,3]) = [1,2,3] + [1,2,3] + [4,5,6] = [1,2,3,1,2,3,4,5,6] ,也可以这样
all_cv_authors_ = sum(data_cv['authors_parsed'])
all_cv_authors_---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-11-40c6e30daeee> in <module>
----> 1 all_cv_authors_ = sum(data_cv['authors_parsed'])
2 all_cv_authors_TypeError: unsupported operand type(s) for +: 'int' and 'list'a = [[1,2,3],[2,3,4],[4,5,6]]
b = [[2,3,4]]
sum(a+b,[])[1, 2, 3, 2, 3, 4, 4, 5, 6, 2, 3, 4]结论
使用sum做加法运算,start的值和迭代器中元素做加法运算,需要满足加法运算要求。按照上面的示例,二维list使用sum可以实现多个list的拼接(其实使用numpy也很方便)。如果遇到其他各种类型迭代器,只要按照定义展开就能轻松搞定内部机理,同时要记得设置start变量的值和迭代器元素类型相同哟!!!,不相同也可以,必须可以做加法运算,C++叫重载。
三、数据可视化
len(cv_authors_names)205345# 拼接所有的作者
cv_authors_names = [' '.join(x) for x in all_cv_authors]
cv_authors_names = pd.DataFrame(cv_authors_names)
cv_authors_names.head()| 0 | |
|---|---|
| 0 | Likforman-Sulem Laurence |
| 1 | Zahour Abderrazak |
| 2 | Taconet Bruno |
| 3 | Nelwamondo Fulufhelo Vincent |
| 4 | Marwala Tshilidzi |
# 展示排名前十的数据
cv_authors_names[0].value_counts().head(10)Shen Chunhua 239
Van Gool Luc 207
Tao Dacheng 168
Zhang Lei 161
Navab Nassir 152
Lin Liang 143
Darrell Trevor 143
Wang Xiaogang 138
Yang Ming-Hsuan 137
Feng Jiashi 134
Name: 0, dtype: int64# 根据作者频率绘制直方图
fig, axes = plt.subplots(figsize=(10,6))
cv_authors_names[0].value_counts().head(10).plot(kind='barh')
# 修改图的配置
plt.ylabel('Author')
plt.xlabel('Count')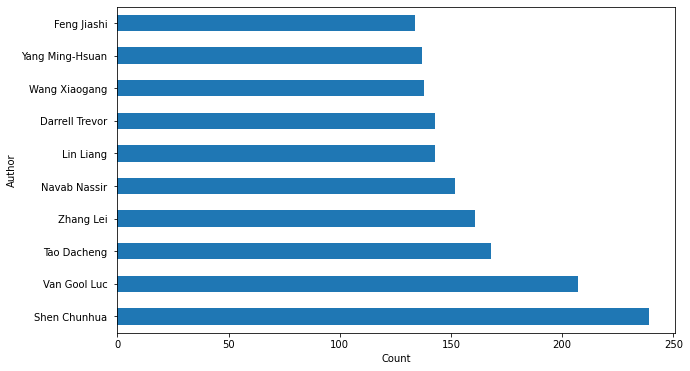
给出几位的巨巨巨巨巨佬的Google Scholar链接
- Chunhua Shen:https://scholar.google.com/citations?user=Ljk2BvIAAAAJ&hl=zh-CN
- Luc Van Gool:https://scholar.google.com/citations?user=TwMib_QAAAAJ&hl=zh-CN
- Dacheng Tao:https://scholar.google.com/citations?user=RwlJNLcAAAAJ&hl=zh-CN
- Lei Zhang:https://scholar.google.com/citations?user=tAK5l1IAAAAJ&hl=zh-CN
- Nassir Navab:https://scholar.google.de/citations?user=kzoVUPYAAAAJ&hl=zh-CN
- Liang Lin:https://scholar.google.com.hk/citations?user=Nav8m8gAAAAJ&hl=zh-CN
- Trevor Darrell:https://scholar.google.com/citations?user=bh-uRFMAAAAJ&hl=zh-CN
cv_authors_lastnames = [x[0] for x in all_cv_authors]
cv_authors_lastnames = pd.DataFrame(cv_authors_lastnames)
cv_authors_lastnames.head()| 0 | |
|---|---|
| 0 | Likforman-Sulem |
| 1 | Zahour |
| 2 | Taconet |
| 3 | Nelwamondo |
| 4 | Marwala |
fig, axes = plt.subplots(figsize=(10,6))
cv_authors_lastnames[0].value_counts().head(10).plot(kind='barh')
plt.ylabel('Author')
plt.xlabel('Count')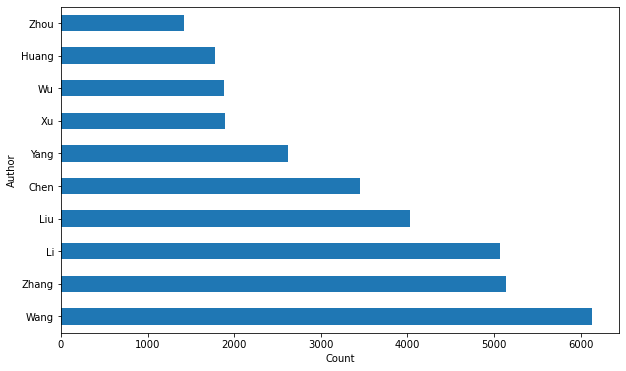
Wang、Zhang、Li 排名前三,这与这三个姓基数多有一定原因



